MAY CONTAIN BAD ASS CONTENT: ANALYST DISCRETION IS ADVISED
Basic Census Analytics with Alteryx
US Census has details on 230,000 areas in the US
From here, I'll walk through the basic workflow and then we can do a deeper dive into how this data set is structured so we can ask more questions.
WORKFLOW WALKTHROUGH
The top leg of the workflow starts with the census questions. This contains all the questions on the 2010 census. We first filter the questions to get questions related to population "TABLE_ID" LIKE B0110%e%. Snowflake uses standard SQL syntax meaning that the % symbol is a wildcard. This says give me all tables starting with B0110 then that have an "e" and then any other value after that. B0110 are all the population related questions and the e means estimate. You can also get m meaning margin of error.
On the bottom leg of the workflow we are going to connect to the responses for the B01 table (this has the answers to each question) - the top leg has the questions themselves. Here we can select the questions we are interested in. In the example it's just total population. But you could easily add other questions like male population between the ages of 22 to 24 by selecting B01001E10, as an example.
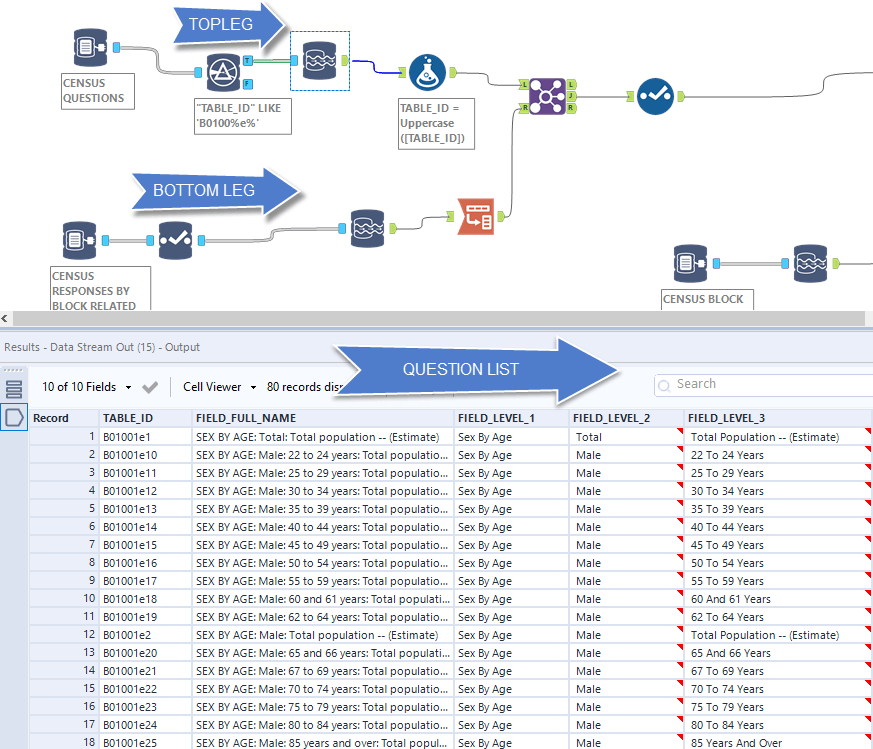
After each leg, we will use the datastream out tool to bring the result set into Alteryx. On the bottom leg, we need a simple pivot to get the question_id as a row instead of a field (header). Joining will bring the question into context of the answer. Then with the select tool we just choose the question context and now we can an answer by census block.
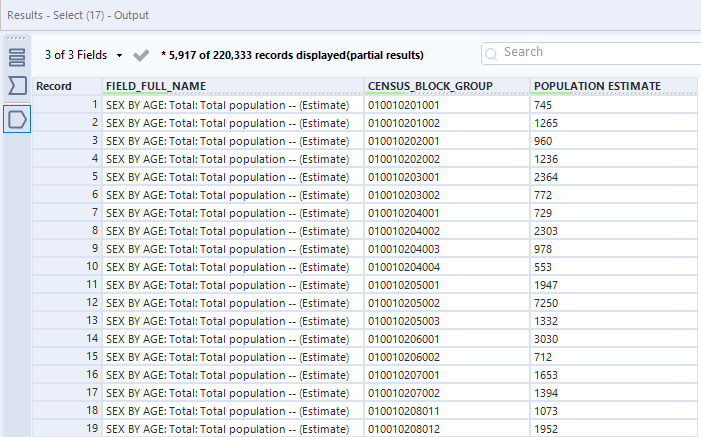
Now a census block isn't very useful to us without context, but there is a census block metadata table as well in the data source, which has details on each census block. That table for reference is "METADATA_CBG_GEOGRAPHIC_DATA"
Downloading this data and joining it back by census group gives you population as well as coordinates and the land area and water area for each census group.
Adding a create points tool from the spatial object bar enables us to transform this data into a map object visible through any browse tool.
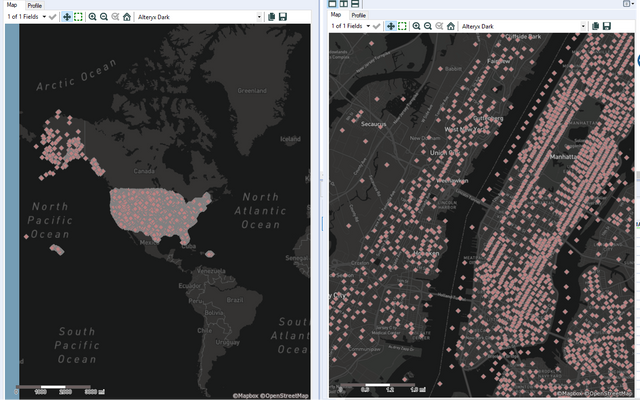
Now that is absurdly detailed!! And remember we have details on this level for over 7,000 individual questions from the census. In future posts we will show how to build this up to aggregate trade areas around your specific locations of interest.